Les tokens d’API Rundeck ont tendance à proliférer silencieusement. Un petit script Python suffit à reprendre le contrôle : lister, créer, supprimer — sans dépendance externe.
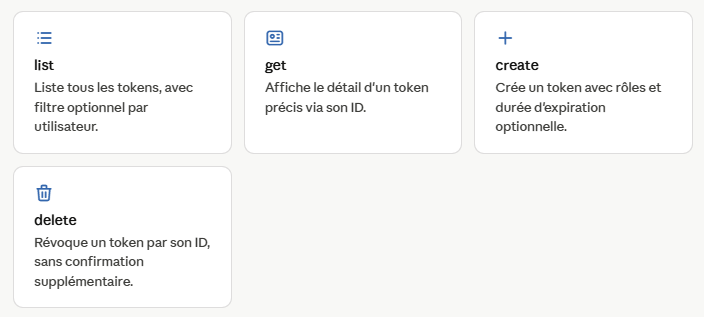
Rundeck expose une API REST complète, mais naviguer dans l’interface web pour auditer des dizaines de tokens devient vite fastidieux. Le script manage_rundeck_tokens.py s’appuie directement sur l’API de rundeck pour automatiser la gestion des tokens — idéal dans un pipeline CI/CD ou une tâche cron.
Le script ne nécessite aucune bibliothèque tierce : il utilise uniquement la stdlib Python (urllib, argparse, json). L’authentification Kerberos est le seul cas qui requiert gssapi.
Le script couvre les principaux modes d’accès à Rundeck :
–token API_TOKEN –login USER (mot de passe interactif) –kerberos (SPNEGO)
Le mode --login gère la session via cookie (endpoint /j_security_check). Le mode --kerberos sonde d’abord le serveur pour vérifier la présence du header Negotiate, et affiche un message d’erreur explicite si SPNEGO n’est pas configuré.
Affichage coloré des expirations
Chaque token affiché en terminal est accompagné d’un statut visuel basé sur sa date d’expiration :
EXPIREDToken arrivé à échéance
CRITICAL — 2jExpiration dans moins de 3 jours
WARNING — 5jExpiration dans moins de 7 jours
OK — 42jToken en bonne santé
Rapport par e-mail
La commande list accepte un flag --email qui génère un rapport HTML et l’envoie via un module compagnon (email_report.py). Couplé à une tâche cron, c’est un moyen simple d’être alerté avant l’expiration d’un token critique.
#!/usr/bin/env python3
"""
Rundeck API Token Manager
Manage Rundeck API tokens (list, create, delete) via the Rundeck REST API v54.
USAGE:
python manage_rundeck_tokens.py --url <URL> <AUTH_METHOD> <COMMAND> [OPTIONS]
AUTHENTICATION METHODS (choose one):
--token APITOKEN Use an existing Rundeck API token
--login USERNAME Use username/password authentication (password will be prompted)
--password PASSWORD Password for --login (optional, will be prompted if omitted)
--kerberos Use current user's Kerberos ticket (requires: pip install gssapi)
COMMANDS:
list [--user USERNAME] List all API tokens (optionally filter by user)
get --id TOKEN_ID Get details for a specific token by ID
create --user USERNAME Create a new API token with roles and optional expiry
--roles ROLE [ROLE...] One or more roles (space-separated, required)
--duration DURATION Token expiry (e.g., 30d, 12h, 1w; omit for no expiry)
delete --id TOKEN_ID Delete a token by its ID
EXAMPLES:
1. List all tokens using an API token:
python manage_rundeck_tokens.py --url http://rundeck:4440 --token MYAPITOKEN list
2. List all tokens using username/password (password will be prompted):
python manage_rundeck_tokens.py --url http://rundeck:4440 --login admin list
3. List tokens for a specific user (admin only):
python manage_rundeck_tokens.py --url http://rundeck:4440 --token MYAPITOKEN list --user alice
4. List tokens and send report by email:
python manage_rundeck_tokens.py --url http://rundeck:4440 --token MYAPITOKEN list --email
5. Get details for a specific token:
python manage_rundeck_tokens.py --url http://rundeck:4440 --token MYAPITOKEN get --id abc123def456
6. Create a new token (non-expiring):
python manage_rundeck_tokens.py --url http://rundeck:4440 --login admin create \
--user alice --roles admin deploy
7. Create a token that expires in 30 days:
python manage_rundeck_tokens.py --url http://rundeck:4440 --login admin create \
--user john --roles developer --duration 30d
8. Create a token with multiple roles and custom password:
python manage_rundeck_tokens.py --url http://rundeck:4440 --login admin --password secret123 create \
--user bob --roles admin deploy execute
9. Delete a token:
python manage_rundeck_tokens.py --url http://rundeck:4440 --token MYAPITOKEN delete \
--id abc123def456
10. Use Kerberos authentication (requires valid ticket via kinit):
python manage_rundeck_tokens.py --url http://rundeck:4440 --kerberos list
11. Use environment variable for token (useful in scripts):
export RUNDECK_TOKEN=MYAPITOKEN
python manage_rundeck_tokens.py --url http://rundeck:4440 --token $RUNDECK_TOKEN list
OUTPUT:
- Tokens are displayed with color-coded expiry status:
* [EXPIRED] in red
* [N days] in red/yellow (< 7 days) or green (>= 30 days)
- Token details include: ID, name, user, roles, expiration date, creator
"""
import argparse
import getpass
import json
import sys
import urllib.request
import urllib.error
import urllib.parse
from http.cookiejar import CookieJar
from datetime import datetime, timezone
from typing import Optional
try:
from email_report import EmailReportSender, generate_rundeck_tokens_report
HAS_EMAIL = True
except ImportError:
HAS_EMAIL = False
def login_with_password(base_url: str, username: str, password: str) -> urllib.request.OpenerDirector:
"""
Authenticate with a Rundeck username/password.
Returns an opener that carries the session cookie for all subsequent calls.
"""
cj = CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
login_url = f"{base_url.rstrip('/')}/j_security_check"
form_data = urllib.parse.urlencode({
"j_username": username,
"j_password": password,
}).encode()
req = urllib.request.Request(login_url, data=form_data, method="POST")
req.add_header("Content-Type", "application/x-www-form-urlencoded")
try:
with opener.open(req) as resp:
# Rundeck redirects to / on success and to /user/error on failure
final_url = resp.geturl()
if "error" in final_url or "login" in final_url:
print("[Auth error] Login failed - check username/password.", file=sys.stderr)
sys.exit(1)
except urllib.error.URLError as e:
print(f"[Connection error] {e.reason}", file=sys.stderr)
sys.exit(1)
print(f"Logged in as '{username}'.")
return opener
def login_with_kerberos(base_url: str) -> urllib.request.OpenerDirector:
"""
Authenticate using SPNEGO/Kerberos (Negotiate scheme).
Requires: pip install gssapi + a valid Kerberos ticket (kinit).
Probes the server first; exits with a clear message if SPNEGO is not
configured on this Rundeck instance.
"""
try:
import base64
import gssapi
except ImportError:
print("[Error] Kerberos auth requires gssapi: pip install gssapi", file=sys.stderr)
sys.exit(1)
parsed = urllib.parse.urlparse(base_url)
probe_url = f"{base_url.rstrip('/')}/api/54/system/info"
# --- Step 1: probe without auth to check for SPNEGO challenge ---
cj = CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
www_auth = ""
try:
probe_req = urllib.request.Request(probe_url, headers={"Accept": "application/json"})
with opener.open(probe_req):
return opener # already authenticated (unlikely)
except urllib.error.HTTPError as e:
www_auth = e.headers.get("WWW-Authenticate", "")
if e.code not in (401, 403):
body = e.read().decode(errors="replace")
print(f"[HTTP {e.code}] {e.reason} - {body}", file=sys.stderr)
sys.exit(1)
if "Negotiate" not in www_auth:
got = www_auth or "none"
print(
"[Kerberos error] This Rundeck instance does not support SPNEGO/Kerberos.\n"
f" No 'WWW-Authenticate: Negotiate' received (got: '{got}').\n"
" The server uses form-based auth only. Use --login <username> instead.",
file=sys.stderr,
)
sys.exit(1)
# --- Step 2: generate GSSAPI token ---
try:
service_name = gssapi.Name(
f"HTTP@{parsed.hostname}",
name_type=gssapi.NameType.hostbased_service,
)
ctx = gssapi.SecurityContext(name=service_name, usage="initiate")
token = ctx.step()
except gssapi.exceptions.GSSError as e:
print(f"[Kerberos error] {e}\nRun: kinit", file=sys.stderr)
sys.exit(1)
negotiate_token = base64.b64encode(token).decode()
# --- Step 3: send authenticated request to obtain session cookie ---
req_auth = urllib.request.Request(
probe_url,
headers={"Authorization": f"Negotiate {negotiate_token}", "Accept": "application/json"},
)
try:
with opener.open(req_auth):
pass # cookie jar captures the session cookie
except urllib.error.HTTPError as e:
if e.code == 401:
print("[Auth error] Kerberos: token rejected (401). Run: klist", file=sys.stderr)
else:
body = e.read().decode(errors="replace")
print(f"[HTTP {e.code}] {e.reason} - {body}", file=sys.stderr)
sys.exit(1)
except urllib.error.URLError as e:
print(f"[Connection error] {e.reason}", file=sys.stderr)
sys.exit(1)
import os
print(f"Authenticated via Kerberos (cache: {os.environ.get('KRB5CCNAME', 'default')}).")
return opener
def make_request(
base_url: str,
method: str,
path: str,
payload: Optional[dict] = None,
api_token: Optional[str] = None,
opener: Optional[urllib.request.OpenerDirector] = None,
) -> dict | list | None:
"""
Perform an API call.
Exactly one of *api_token* or *opener* (session cookie) must be provided.
"""
url = f"{base_url.rstrip('/')}{path}"
headers: dict[str, str] = {
"Accept": "application/json",
"Content-Type": "application/json",
}
if api_token:
headers["X-Rundeck-Auth-Token"] = api_token
data = json.dumps(payload).encode() if payload else None
req = urllib.request.Request(url, data=data, headers=headers, method=method)
_opener = opener or urllib.request.build_opener()
try:
with _opener.open(req) as resp:
body = resp.read()
if body:
return json.loads(body)
return None
except urllib.error.HTTPError as e:
body = e.read().decode(errors="replace")
print(f"[HTTP {e.code}] {e.reason} - {body}", file=sys.stderr)
sys.exit(1)
except urllib.error.URLError as e:
print(f"[Connection error] {e.reason}", file=sys.stderr)
sys.exit(1)
# ---------------------------------------------------------------------------
# Shorthand - forwards auth kwargs to make_request
# ---------------------------------------------------------------------------
def _req(base_url, method, path, payload=None, **auth):
return make_request(base_url, method, path, payload, **auth)
# ---------------------------------------------------------------------------
# API operations
# ---------------------------------------------------------------------------
def list_tokens(base_url: str, user: Optional[str] = None, **auth) -> list:
"""List all tokens, or only those belonging to *user*."""
path = "/api/54/tokens"
if user:
path += f"/{user}"
result = _req(base_url, "GET", path, **auth)
# Rundeck returns {"tokens": [...]} or a bare list depending on version
if isinstance(result, dict):
return result.get("tokens", [])
return result or []
def get_token(base_url: str, token_id: str, **auth) -> dict:
"""Get details for a single token by its ID."""
return _req(base_url, "GET", f"/api/54/token/{token_id}", **auth)
def create_token(
base_url: str,
user: str,
roles: list[str],
duration: Optional[str] = None,
name: Optional[str] = None,
**auth,
) -> dict:
"""
Create a new token.
Parameters
----------
user : Rundeck username the token is associated with.
roles : List of role names (e.g. ["admin", "deploy"]).
duration : Optional expiry expressed as a Rundeck duration string,
e.g. "30d", "12h", "1w". Omit for a never-expiring token.
name : Optional custom name for the token.
"""
payload: dict = {"user": user, "roles": roles}
if duration:
payload["duration"] = duration
if name:
payload["name"] = name
return _req(base_url, "POST", "/api/54/tokens", payload, **auth)
def delete_token(base_url: str, token_id: str, **auth) -> None:
"""Delete a token by its ID."""
_req(base_url, "DELETE", f"/api/54/token/{token_id}", **auth)
print(f"Token '{token_id}' deleted successfully.")
# ---------------------------------------------------------------------------
# Pretty-printing
# ---------------------------------------------------------------------------
# ANSI colour codes
_RESET = "\033[0m"
_RED = "\033[1;31m"
_YELLOW = "\033[1;33m"
_GREEN = "\033[1;32m"
def _expiry_status(expiration: str) -> tuple[str, str]:
"""Return (label, colour) based on days until expiry."""
try:
exp = datetime.fromisoformat(expiration.replace("Z", "+00:00"))
now = datetime.now(timezone.utc)
days = (exp - now).days
if days < 0:
return "[EXPIRED]", _RED
elif days < 3:
return f"[CRITICAL - expires in {days}d]", _RED
elif days < 7:
return f"[WARNING - expires in {days}d]", _YELLOW
else:
return f"[OK - expires in {days}d]", _GREEN
except (ValueError, AttributeError):
return "", _RESET
def print_token(token: dict) -> None:
# Determine expiration status for the header
colour = _RESET
status_label = ""
if token.get("expiration"):
status_label, colour = _expiry_status(token["expiration"])
elif token.get("expired") is True:
status_label, colour = "[EXPIRED]", _RED
print(f"{colour}" + "-" * 60 + f" {status_label}{_RESET}")
for key in ("id", "name", "user", "roles", "expiration", "expired", "creator", "token"):
if key not in token:
continue
value = token[key]
if key == "expiration" and isinstance(value, str) and value:
value = value[:10] # Keep only YYYY-MM-DD
line = f" {key:<12}: {value}"
if key in ("expiration", "expired") and colour != _RESET:
print(f"{colour}{line}{_RESET}")
else:
print(line)
# ---------------------------------------------------------------------------
# CLI
# ---------------------------------------------------------------------------
def build_parser() -> argparse.ArgumentParser:
parser = argparse.ArgumentParser(
description="Manage Rundeck API tokens (list / create / delete).",
formatter_class=argparse.RawDescriptionHelpFormatter,
epilog="""
Authentication - choose one method:
--token APITOKEN Use a Rundeck API token
--login USER [--password P] Use a username/password (password prompted if omitted)
--kerberos Use the current user Kerberos ticket (SPNEGO/Negotiate)
Examples:
# List all tokens (API token auth)
python rundeck_tokens.py --url http://rundeck:4440 --token MYAPITOKEN list
# List tokens (login/password auth, password will be prompted)
python rundeck_tokens.py --url http://rundeck:4440 --login admin list
# List tokens for a specific user
python rundeck_tokens.py --url http://rundeck:4440 --token MYAPITOKEN list --user alice
# List tokens and send report by email
python rundeck_tokens.py --url http://rundeck:4440 --token MYAPITOKEN list --email
# Create a token (expires in 30 days)
python rundeck_tokens.py --url http://rundeck:4440 --login admin create \\
--user alice --roles admin deploy --duration 30d
# Delete a token by ID
python rundeck_tokens.py --url http://rundeck:4440 --token MYAPITOKEN delete \\
--id abc123def456
""",
)
parser.add_argument(
"--url",
required=True,
help="Rundeck base URL, e.g. http://rundeck:4440",
)
auth_group = parser.add_mutually_exclusive_group(required=True)
auth_group.add_argument(
"--token",
metavar="APITOKEN",
help="Rundeck API token used to authenticate requests.",
)
auth_group.add_argument(
"--login",
metavar="USERNAME",
help="Rundeck username for login/password authentication.",
)
auth_group.add_argument(
"--kerberos",
action="store_true",
help="Use the current user Kerberos ticket (SPNEGO). Requires: pip install gssapi",
)
parser.add_argument(
"--password",
metavar="PASSWORD",
default=None,
help="Password for --login auth. If omitted, you will be prompted (recommended).",
)
sub = parser.add_subparsers(dest="command", required=True)
# --- list ---
p_list = sub.add_parser("list", help="List API tokens.")
p_list.add_argument(
"--user",
default=None,
help="Filter tokens by username (optional, admin only for other users).",
)
p_list.add_argument(
"--email",
action="store_true",
help="Send the token report by email (requires email_report module and SMTP environment variables).",
)
p_list.add_argument(
"--report-path",
default=None,
type=str,
help="Save the HTML report to a file (optional, used with --email).",
)
# --- get ---
p_get = sub.add_parser("get", help="Show details for a single token.")
p_get.add_argument("--id", required=True, metavar="TOKEN_ID", help="Token ID.")
# --- create ---
p_create = sub.add_parser("create", help="Create a new API token.")
p_create.add_argument("--user", required=True, help="Username to associate with the token.")
p_create.add_argument(
"--roles",
nargs="+",
required=True,
metavar="ROLE",
help="One or more roles to assign (space-separated).",
)
p_create.add_argument(
"--duration",
default=None,
help="Expiry duration, e.g. 30d, 12h, 1w. Omit for no expiry.",
)
p_create.add_argument(
"--name",
default=None,
help="Optional custom name for the token.",
)
# --- delete ---
p_delete = sub.add_parser("delete", help="Delete an API token.")
p_delete.add_argument("--id", required=True, metavar="TOKEN_ID", help="Token ID to delete.")
return parser
def main() -> None:
parser = build_parser()
args = parser.parse_args()
# --- Build auth kwargs passed to every API call ---
if args.token:
auth = {"api_token": args.token}
elif args.kerberos:
session_opener = login_with_kerberos(args.url)
auth = {"opener": session_opener}
else:
password = args.password or getpass.getpass(f"Password for '{args.login}': ")
session_opener = login_with_password(args.url, args.login, password)
auth = {"opener": session_opener}
if args.command == "list":
# For list, the optional --user filter lives on the subcommand
tokens = list_tokens(args.url, getattr(args, "user", None), **auth)
if not tokens:
print("No tokens found.")
else:
print(f"Found {len(tokens)} token(s):")
for t in tokens:
print_token(t)
# Send email report if requested
if getattr(args, "email", False):
if not HAS_EMAIL:
print("\n? [Error] Email module not available. Please check that email_report.py is in the same directory.", file=sys.stderr)
sys.exit(1)
print("\n?? Generating email report...")
# Generate HTML report
report_html = generate_rundeck_tokens_report(
tokens=tokens,
base_url=args.url
)
# Save to file if requested
if getattr(args, "report_path", None):
try:
with open(args.report_path, 'w', encoding='utf-8') as f:
f.write(report_html)
print(f"? Report saved to: {args.report_path}")
except Exception as e:
print(f"? Error saving report: {e}", file=sys.stderr)
sys.exit(1)
# Send email
try:
sender = EmailReportSender()
subject = f"Rundeck API Tokens Report - {datetime.now().strftime('%d/%m/%Y')}"
success = sender.send_simple_report(
subject=subject,
html_body=report_html
)
if not success:
print("[ERROR] Failed to send email", file=sys.stderr)
sys.exit(1)
except Exception as e:
print(f"[ERROR] Error sending email: {e}", file=sys.stderr)
sys.exit(1)
elif args.command == "get":
token = get_token(args.url, args.id, **auth)
print_token(token)
elif args.command == "create":
new_token = create_token(
args.url, args.user, args.roles, args.duration, args.name, **auth
)
print("Token created:")
print_token(new_token)
elif args.command == "delete":
delete_token(args.url, args.id, **auth)
if __name__ == "__main__":
main()
#!/usr/bin/env python3
"""
Module d'envoi de rapports par email avec timeout strict
"""
import smtplib
import os
import socket
import threading
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.mime.base import MIMEBase
from email import encoders
from pathlib import Path
from datetime import datetime
from typing import Optional, List
class EmailReportSender:
"""Classe pour envoyer des rapports par email avec HTML et pieces jointes"""
def __init__(self, smtp_server: str = None, smtp_port: int = None,
from_email: str = None, to_email: str = None, use_tls: bool = False):
"""Initialise le sender avec la config SMTP"""
self.smtp_server = smtp_server or os.getenv('SMTP_SERVER', 'localhost')
self.smtp_port = int(smtp_port or os.getenv('SMTP_PORT', 25))
self.from_email = from_email or os.getenv('FROM_EMAIL', 'monitoring@example.com')
self.to_email = to_email or os.getenv('TO_EMAIL', 'admin@example.com')
self.use_tls = use_tls
def send_simple_report(self, subject: str, html_body: str, text_body: Optional[str] = None,
attachments: Optional[List[str]] = None, cc: Optional[str] = None,
bcc: Optional[str] = None) -> bool:
"""Envoie un email simple avec rapport HTML"""
try:
msg = MIMEMultipart('alternative')
msg['Subject'] = subject
msg['From'] = self.from_email
msg['To'] = self.to_email
if cc:
msg['Cc'] = cc
if bcc:
msg['Bcc'] = bcc
if text_body:
msg.attach(MIMEText(text_body, 'plain', 'utf-8'))
else:
text_fallback = self._html_to_text(html_body)
msg.attach(MIMEText(text_fallback, 'plain', 'utf-8'))
msg.attach(MIMEText(html_body, 'html', 'utf-8'))
if attachments:
for attachment_path in attachments:
if Path(attachment_path).exists():
self._attach_file(msg, attachment_path)
recipients = [self.to_email]
if cc:
recipients.extend([e.strip() for e in cc.split(',')])
if bcc:
recipients.extend([e.strip() for e in bcc.split(',')])
msg_string = msg.as_string()
return self._send_with_timeout(recipients, msg_string, timeout=5)
except Exception as e:
print(f"[ERROR] Error preparing email: {e}")
return False
def _send_with_timeout(self, recipients, msg_string, timeout=5):
"""Envoie email dans un thread avec timeout strict"""
result = {'sent': False, 'error': None}
def send_thread():
try:
print(f" [INFO] Checking socket on {self.smtp_server}:{self.smtp_port}...")
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(timeout)
sock.connect((self.smtp_server, self.smtp_port))
sock.close()
with smtplib.SMTP(self.smtp_server, self.smtp_port, timeout=timeout) as server:
if self.use_tls:
server.starttls()
server.sendmail(self.from_email, recipients, msg_string)
result['sent'] = True
except socket.timeout:
result['error'] = f"Timeout: {self.smtp_server}:{self.smtp_port} no response in {timeout}s"
except socket.gaierror:
result['error'] = f"Host not found: {self.smtp_server}"
except ConnectionRefusedError:
result['error'] = f"Connection refused: {self.smtp_server}:{self.smtp_port}"
except socket.error as e:
result['error'] = f"Socket error: {e}"
except smtplib.SMTPException as e:
result['error'] = f"SMTP error: {e}"
except Exception as e:
result['error'] = f"Error: {type(e).__name__}: {e}"
thread = threading.Thread(target=send_thread, daemon=True)
thread.start()
thread.join(timeout=timeout + 2)
if thread.is_alive():
print(f"[ERROR] Timeout after {timeout + 2}s - server not responding")
return False
if result['sent']:
print(f"[SUCCESS] Email sent successfully")
return True
else:
print(f"[ERROR] {result['error']}")
return False
@staticmethod
def _attach_file(msg, file_path: str):
"""Attach file to message"""
part = MIMEBase('application', 'octet-stream')
with open(file_path, 'rb') as attachment:
part.set_payload(attachment.read())
encoders.encode_base64(part)
part.add_header('Content-Disposition', f'attachment; filename={Path(file_path).name}')
msg.attach(part)
@staticmethod
def _html_to_text(html):
"""Convert HTML to text"""
import re
text = re.sub('<[^<]+?>', '', html)
text = re.sub(r'\n\s*\n', '\n\n', text)
return text.strip()
def _get_expiry_status_for_html(expiration_str):
"""Return (label, color_hex) based on days until expiry - matching CLI behavior"""
try:
from datetime import timezone
exp = datetime.fromisoformat(expiration_str.replace("Z", "+00:00"))
# Handle naive datetime (simple date without timezone info)
if exp.tzinfo is None:
exp = exp.replace(tzinfo=timezone.utc)
now = datetime.now(timezone.utc)
days = (exp - now).days
if days < 0:
return "[EXPIRED]", "#d32f2f"
elif days < 3:
return f"[CRITICAL – expires in {days}d]", "#d32f2f"
elif days < 7:
return f"[WARNING – expires in {days}d]", "#f57c00"
else:
return f"[OK – expires in {days}d]", "#388e3c"
except (ValueError, AttributeError, TypeError):
return "", "#000000"
def generate_rundeck_tokens_report(tokens, base_url="", timestamp=None):
"""Generate HTML report for Rundeck tokens matching CLI display"""
if not timestamp:
timestamp = datetime.now().strftime("%d/%m/%Y %H:%M:%S")
total = len(tokens)
expired = sum(1 for t in tokens if t.get('expired'))
active = total - expired
html = f"""<html>
<head>
<meta charset="UTF-8">
<style>
body {{ font-family: Courier New, monospace; margin: 20px; background-color: #f5f5f5; }}
h1 {{ color: #0066cc; font-size: 18px; font-weight: bold; }}
h2 {{ color: #333; font-size: 14px; font-weight: bold; margin-top: 20px; }}
.summary {{ margin: 15px 0; }}
.summary-item {{ margin: 5px 0; }}
.token-container {{ margin: 15px 0; background-color: white; border: 1px solid #ddd; border-radius: 4px; }}
.token-header {{ background-color: #f0f0f0; padding: 10px; border-bottom: 1px solid #ddd; font-weight: bold; }}
.token-content {{ padding: 10px; }}
.token-field {{ margin: 5px 0; }}
.token-label {{ display: inline-block; width: 120px; font-weight: bold; }}
.token-value {{ display: inline-block; word-break: break-all; }}
.separator {{ border-top: 1px solid #ccc; margin: 10px 0; }}
</style>
</head>
<body>
<h1>Rundeck API Tokens Report</h1>
<p><strong>Date:</strong> {timestamp}</p>
<p><strong>Server:</strong> {base_url}</p>
<h2>Summary</h2>
<div class="summary">
<div class="summary-item"><strong>Total tokens:</strong> {total}</div>
<div class="summary-item"><strong>Active:</strong> {active}</div>
<div class="summary-item"><strong>Expired:</strong> {expired}</div>
</div>
<h2>Details</h2>
"""
for idx, token in enumerate(tokens, 1):
status_label = ""
status_color = "#000000"
if token.get("expiration"):
status_label, status_color = _get_expiry_status_for_html(token["expiration"])
elif token.get("expired") is True:
status_label, status_color = "[EXPIRED]", "#d32f2f"
html += f"""<div class="token-container">
<div class="token-header" style="color: {status_color};">
Token #{idx} – {status_label}
</div>
<div class="token-content">
"""
token_fields = ["id", "name", "user", "roles", "expiration", "expired", "creator", "token"]
for field in token_fields:
if field not in token:
continue
value = token[field]
if field == "expiration" and isinstance(value, str) and value:
value = value[:10]
elif field == "roles" and isinstance(value, list):
value = ", ".join(value)
style = ""
if field in ("expiration", "expired") and status_color != "#000000":
style = f" style='color: {status_color}; font-weight: bold;'"
html += f""" <div class="token-field"{style}>
<span class="token-label">{field:12s}:</span> <span class="token-value">{value}</span>
</div>
"""
html += """ </div>
<div class="separator"></div>
</div>
"""
html += """</body>
</html>"""
return html