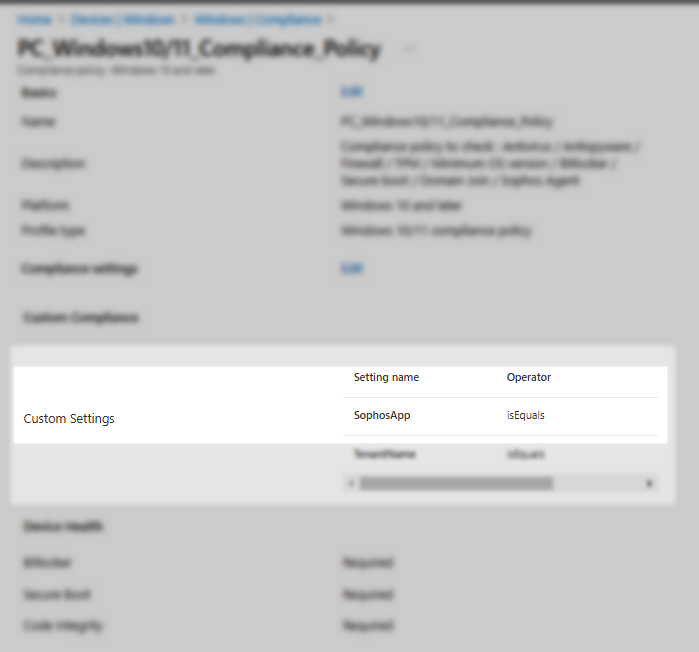
Dans Intune, nous pouvons utiliser les règles de conformité afin de détecter les appareils qui ne répondent pas aux exigences de l’entreprise.
Ces règles de conformité ont des paramètres par défaut, mais on peut créer nos paramètres personnalisés.
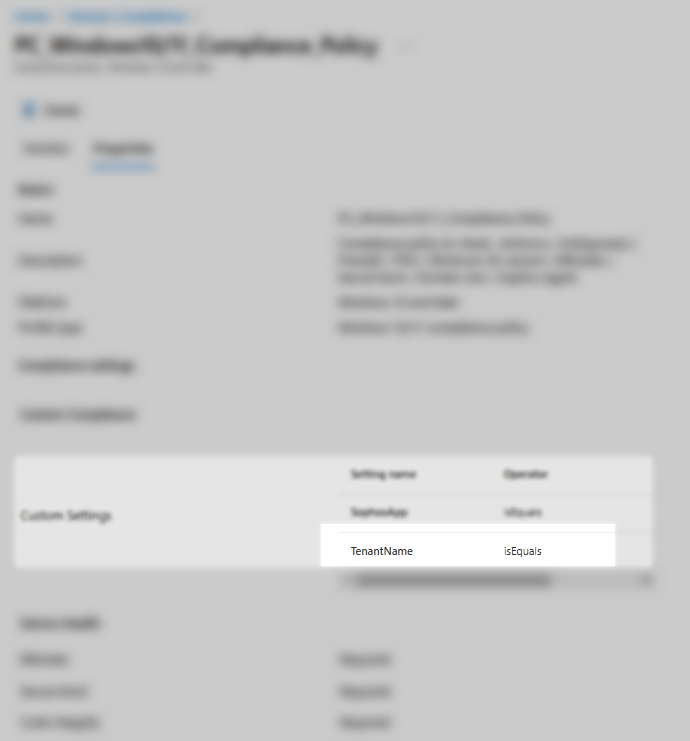
Dans cet article, nous allons configurer un paramètre personnalisé de conformité afin de détecter les appareils qui l’antivirus de l’entreprise installé.
Le script pour détecter l’installation de l’Antivirus est le suivant :
N.B : Dans cet exemple, l’antivirus est Sophos :
### SOPHOS ANTIVIRUS
$SophosApp = (Get-ItemProperty "HKLM:\Software\Microsoft\Windows\CurrentVersion\Uninstall\Sophos Endpoint Agent" -ErrorAction Ignore | Select PSChildName).PSChildName
$hash = @{"SophosApp" = $SophosApp}
return $hash | ConvertTo-Json -Compress
Ce script sera configuré dans : Intune –> Compliance –> Scripts
Une fois créé, ce script nous servira comme paramètre personnalisé dans notre règle de conformité (personnalisée) dans : Intune –> Compliance –> Policies